
Logging, Tracing, Metric 의 개념 및 차이점
시스템 관리자이든 개발자이든 동작 중인 소프트웨어의 작동 방식을 이해하고 싶을 것입니다.
단일 마이크로서비스 부터 방대한 모놀리식 시스템에 이르기까지 Logging, Tracing 및 Monitoring은 모두 시스템의 정확성을 보장하고, 문제가 발생할 때 무엇이 잘못되었는지 추적하고, 전체 기능을 개선하는 데 도움이 되는 모든 방법입니다.
중요한 것은 Logging, Tracing 및 Monitoring이 동일한 프로세스이며, 다른 단어가 아니라는 것 입니다. 단지 각각 고유한 방식으로 작동하는 것입니다.
이러한 작업들의 목적
Investigate(Diagnostics) 가 목적입니다. 조사할 수 있고, 진단할 수 있는 것이 목적입니다. Investigate 후 장애상황 발생시, Alarm과 연동하면 MTTD를 줄일 수 있습니다. (Tracing 사용시 MTTR도 줄일 수 있음)
Logging 이란?
로깅의 목적은 오류 보고 및 관련 데이터를 중앙 집중식으로 추적하는 것입니다. 로깅은 큰 응용 프로그램에서 사용해야 하며 특히 중요한 기능을 제공하는 경우 작은 응용 프로그램에서 사용할 수 있습니다. 로깅이라는 용어는 이벤트 로깅의 실행 또는 결과적으로 발생하는 실제 로그 파일 을 모두 참조할 수 있습니다.
로그 파일은 오류 또는 상태 변환과 같은 응용 프로그램 또는 시스템 내의 개별 이벤트를 표시할 수 있습니다. 불가피하게 문제가 발생했을 때 이러한 상태 변환은 실제로 오류를 일으킨 변경 사항을 나타냅니다.
로깅은 주로 운영 수준에서 시스템 관리자가 배포하고 사용하며 의도적으로 높은 수준의 보기를 제공합니다. 가장 성공적인 로그 파일은 노이즈가 없습니다. 관련이 없거나 주의를 산만하게 하는 정보를 포함해서는 안 됩니다. 대신 로그 파일은 실행 가능한 항목과 같이 절대적으로 필요한 항목만 기록해야 합니다.
이러한 작업 관련 항목 중 두 가지 유형의 데이터가 있을 수 있습니다.
- 현재 동작 상황을 기록하는, 사람이 해석할 수 있는 데이터 (문제 발생시 조사를 시작할 수 있지만 엄청 자세한 정보는 아님. access_log, error_log 등)
- 구조화된 기계 데이터

< 일반적인 access_log. 한줄 텍스트 >
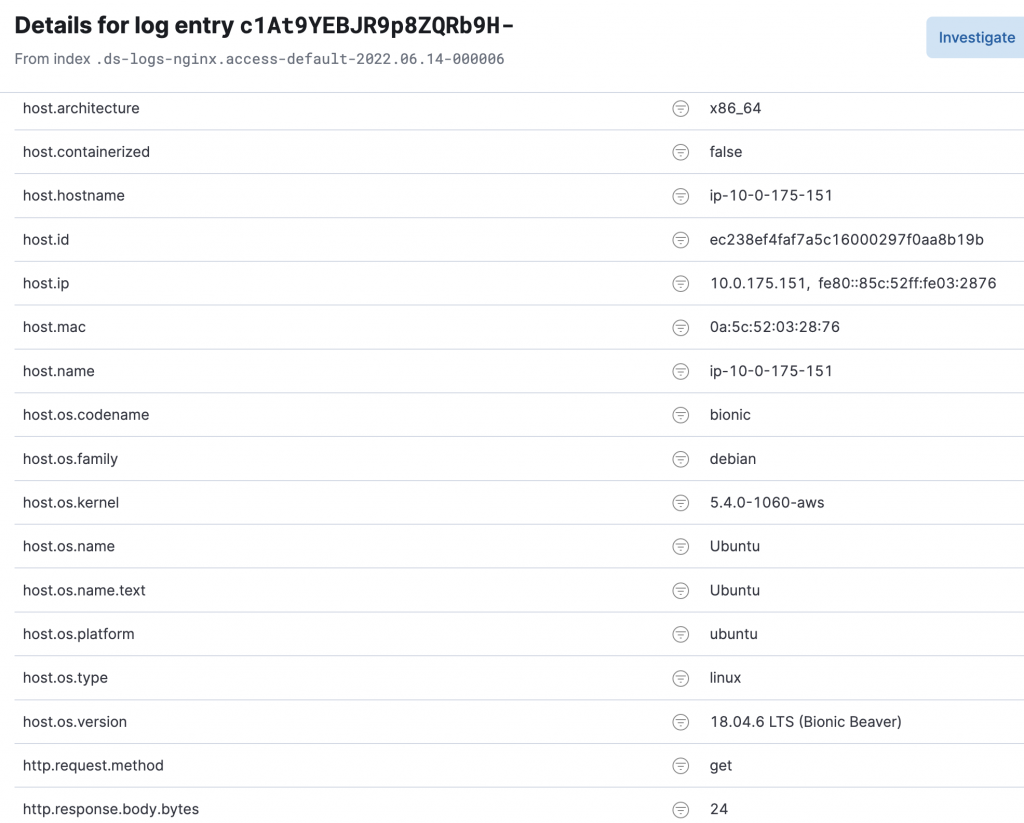
< 구조화된 로그를 사용한 데이터. 주로 json 을 사용함 >
로깅은 간결하면서도 자세한(!) 정보를 기록해야 합니다. 다음의 사항을 고려해보세요.
- 누가 로그 파일을 사용하는지 (주로 시스템관리자가 분석 및 모니터링하는 용도로 사용함)
- 로그 파일을 사용해서 문제 발생을 예방하고, 문제 발생시 추적할 수 있는지 (쓸모가 있어야함)
- 로그의 중요성에 따라 구분해야 하는지? (general_log, audit_log 등. 중요한 이벤트는 따로 로깅하자.)
- 새로운 이벤트가 즉시 기록될 필요는 없음. (일반적으로 수초 ~ 수분의 딜레이가 있음)
너무 많은 데이터를 기록하면 주의가 산만해지고 리소스가 제대로 사용되지 않을 수 있습니다.
실제로 로그를 전송(transfer), 저장(store) 및 구문 분석(parsing & pipeline)하는 데 비용이 많이 들기 때문에, 로그 파일에 포함된 내용을 최소화하면 비용과 리소스를 절약할 수 있습니다.
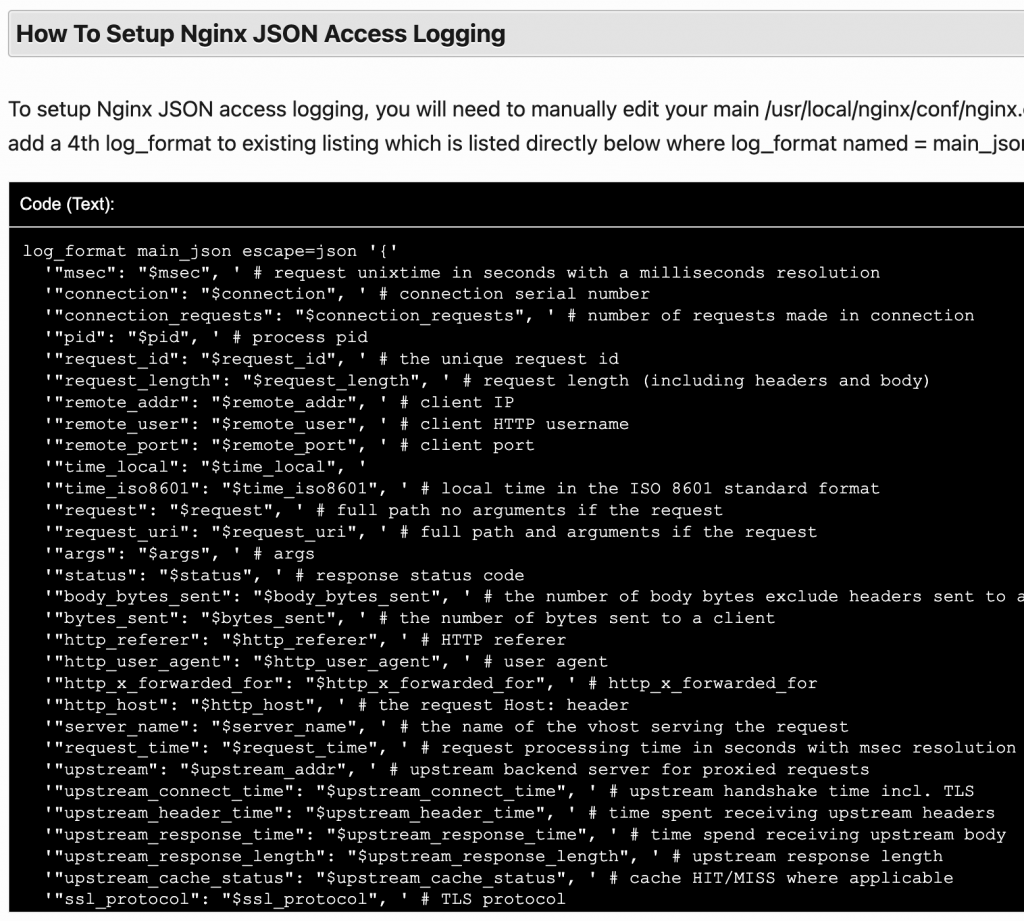
https://community.centminmod.com/threads/how-to-configure-nginx-for-json-based-access-logging.19641/
지나치게 잘 구조화된 human readable 로그는 파일크기가 크고, 처리에 비용이 많이듭니다. (지나치게 JSON 로그 남발하지 말것. 쓰지도 못하는 데이터 기록하지 말것.)
Logging 을 구축 할때 운영자(sysadmin, devops, operator)는 다음을 고려해야함
- 로그 수집
- 로그 중앙 통합 관리
- 로그 보관
- 로그 분석/시각화/트러블 슈팅 (Logging 후처리. Metric, Tracing, Monitoring 영역)
< 다양한 자유형식 로그파일들이 있다. (free form text event log)가 있다 >
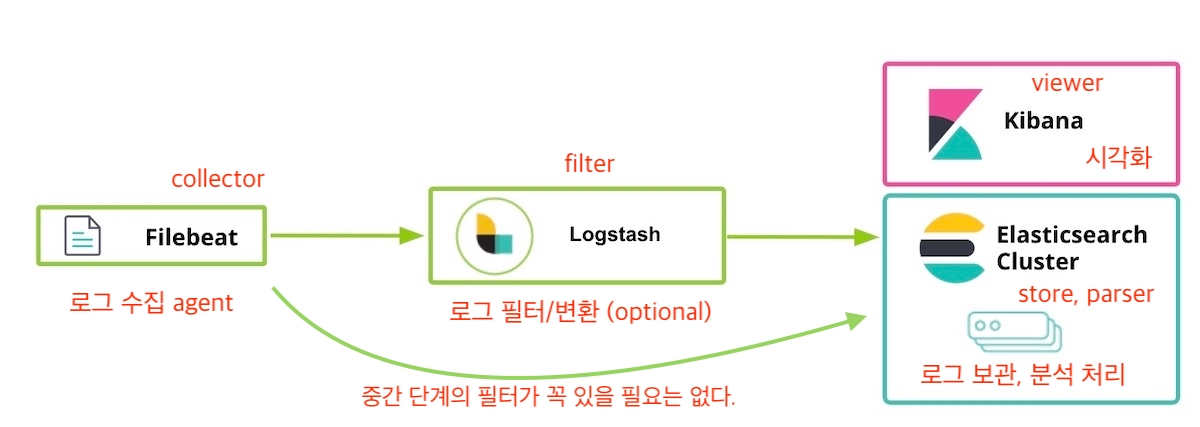
< 일반적인 로그수집 프로세스 >
로그 프로세스에서 가장 중요한 부분은 Store, Parser(coordinator) 이다.
Enterprise 에서 사용하는 계층
- Hot data and Content tier : 데이터를 수집하고 처리하는 계층. 필수적으로 구축하는 서버. General Purpose SSD 서버로 구성. 고성능 필요. 일반적으로 Multi-zone 으로 구성.
- Warm data tier : 덜 빈번하게 사용되는 데이터 계층. Hot tier 보다 CPU 및 Memory 가 낮은 서버로 구성됨. (비용 절약)
- Cold data tier : 드물게 사용되는 데이터 계층. Warm tier 보다 Disk 성능까지 낮춤. (비용 절약)
- Frozen data tier : 거의 사용되지 않는 데이터 계층. 데이터를 즉시 사용할 수 없는 snapshot 형태로 저장하며, 로드 후에 사용할 수 있음.
- Coordinating tier : 데이터 처리 요청(주로 kibana에서의 요청)에 대하여 Hot tier 가 과부화 상태거나, tier 가 복잡할 경우 사용되는 dedicated processing 서버.
- Machine Learning tier : 특정한 경우에, 규칙에 의한 parser 이외의 수치를 얻어야 할 경우에 사용.
쇼핑몰 주문내역을 예로 들자면, 현재 진행중인 주문내역(Hot data tier), 6개월 기간의 지난 주문 내역(warm data tier), 5년 ~ 6개월 지난 주문 내역(cold data tier), 5년이상 (고객에게 제공하지 않음) (frozen data tier).
구축이 귀찮거나 트래픽이 낮으면 Hot 하나로만 운영해도 된다. 하지만 멀티 계층을 하면 Hot 계층의 부하가 줄어들고 전체적인 운영 비용이 줄어든다.
Tracing 이란?
Logging이 개별 이벤트 트리거 로그에 대한 개요를 제공하는 반면, Tracing은 애플리케이션에 대한 훨씬 더 넓고 지속적인 보기를 포함합니다.
추적의 목표는 프로그램의 흐름과 데이터 진행을 따르는 것입니다. 따라서 더 많은 정보가 있습니다. Tracing은 Logging보다 Event에 대해 훨씬 더 자세하게 기록합니다.
많은 경우에 Tracing 은 전체 앱 스택을 통한 단일 사용자의 여정을 나타냅니다. Tracing은 프로세스의 최적화에 중점을 둡니다. 스택을 추적하여 개발자는 병목 현상을 식별하고 성능 개선에 집중할 수 있습니다.
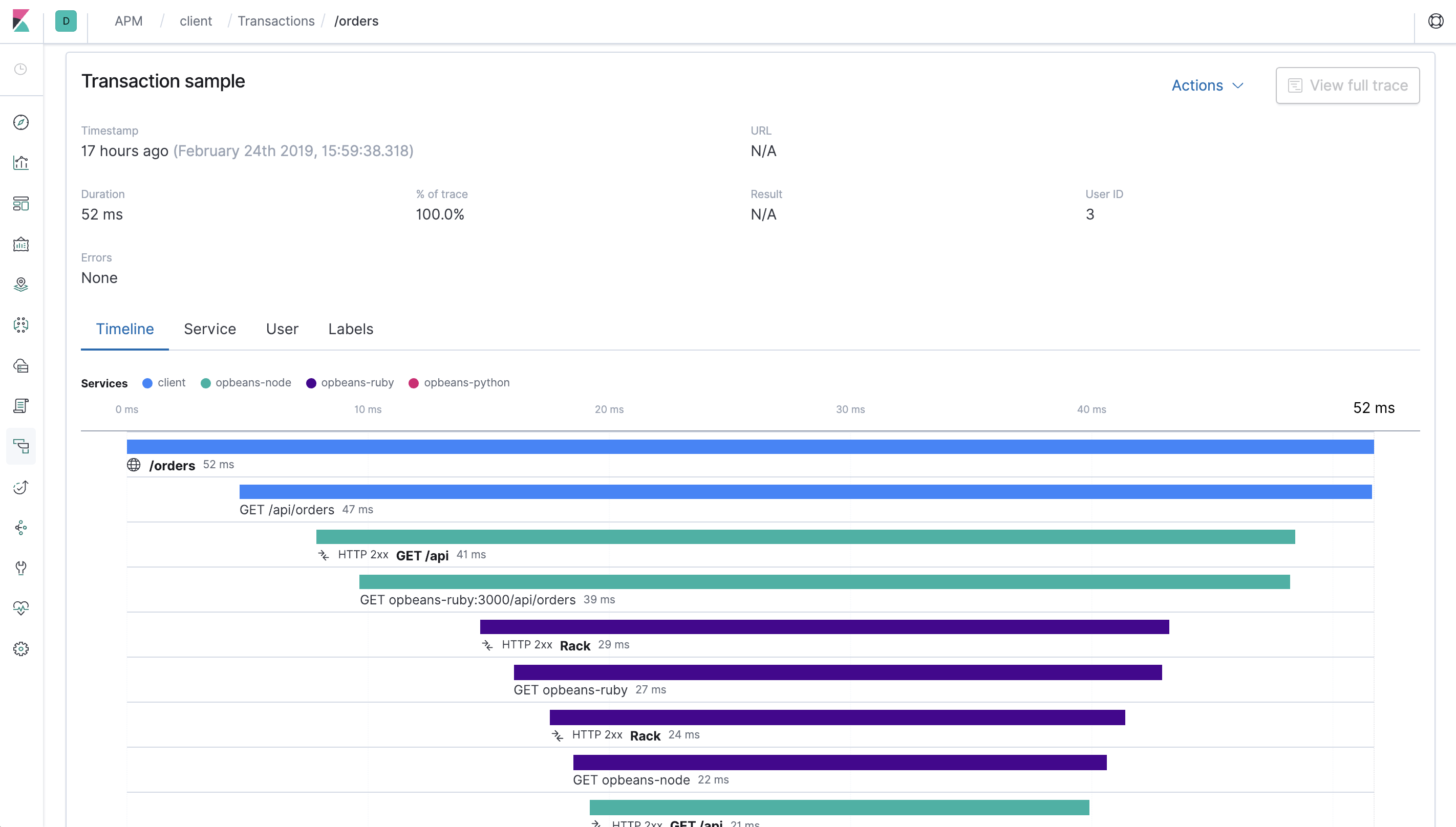
어떤 문제가 발생했을 경우, Tracing 을 통해 문제가 발생한 경로를 확인할 수 있습니다. (Investgate 할 수 있어야함)
일반적으로 Tracing 은 다음의 정보를 가지고 있습니다.
- 함수 이름
- 함수의 실행시간
- 전달된 파라미터
- 호출 경로 (call stack)
이상적으로는 모든 서비스 동작에 대해 Tracing을 하는것이 좋습니다. (tracing 부하가 생각보다 많이 걸리지는 않음)
Tracing 을 도입하기 어려운 경우
- 복잡한 레이어 (사용자 여정 기록이 쉽지 않음)
- 소프트웨어 엔진마다 구현해야함
- (코드/ 프로젝트의) 디자인 모델, 푸쉬 모델 (특히, 비동기 방식의 Domain Driven이나, Event Driven 방식) (데이터 처리되는 방식이 추적이 어려움)
Tracing은 필수 사항이 아닙니다. 그런데 잘 구성된 Tracing은 서비스 최적화에 큰 도움이 됩니다.
일부 경우에는 Tracing을 통한 섣부른 최적화보다, 수평 확장(scale-out, autoscaling)이 더 나을수도 있습니다. (전적으로 운영자의 영역. 전략을 잘 짜야함.)
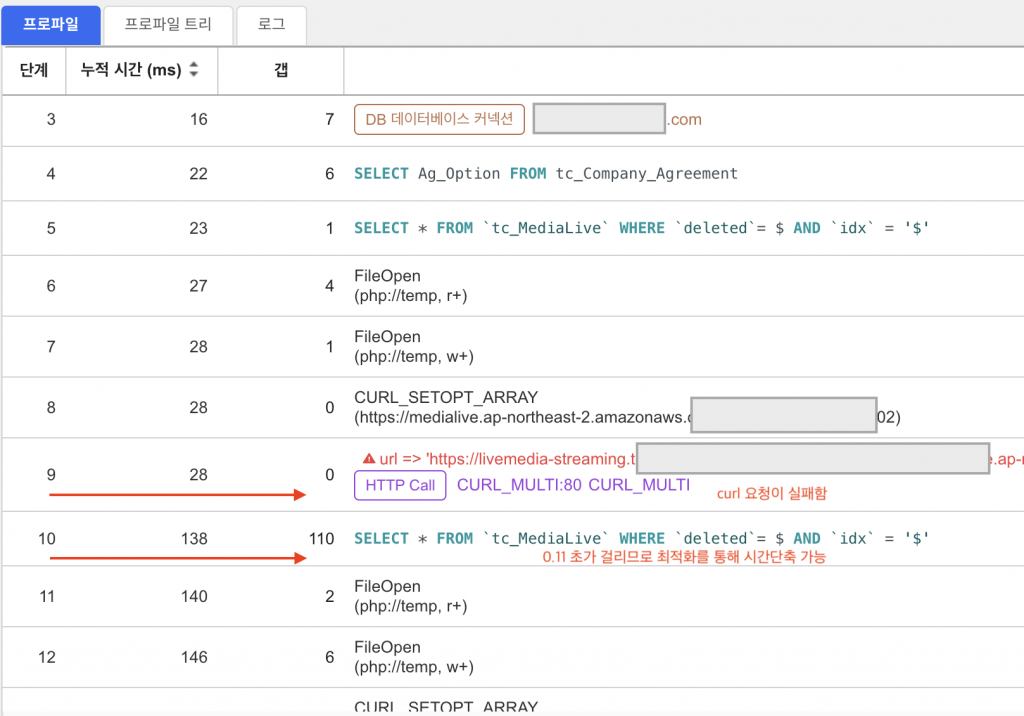
< Tracing 을 사용하면 페이지(API 응답요청) 등이 왜 느린지? 에 대해 파악할 수 있습니다. >
제 경험상, 웹 서비스의 경우에는 MVC, MVVM 등 단순한 구조이기 때문에, 함수 단위의 Tracing 보다는 코드 외적인 연결(DB, CURL, FILE IO)등의 시간과 결과를 측정하여 기록하는 것이 문제 해결에 도움이 되었습니다.
Monitoring(Metric) 이란?
Monitoring 은 Application에서 일정 항목에 대해서 수치를 측정하고 집계 및 분석 하여 시스템이 작동합니다.
이 분석되는 수치를 Metric 이라고 합니다.
이러한 유형의 모니터링은 기본적으로 진단입니다. 예를 들어 시스템이 제대로 작동하지 않을 때 개발자에게 경고합니다. 비용이 문제가 되지 않는 이상적인 세상에서는 모든 서비스를 계측하고 Monitoring 하는 것이 좋습니다.
모니터링 시스템은 데이터에 크게 의존하지만 놀라울 정도로 저렴합니다. 기업이 클라우드와 데이터를 수용할수록 데이터가 많을수록 모니터링에 더 유리할 수 있습니다.
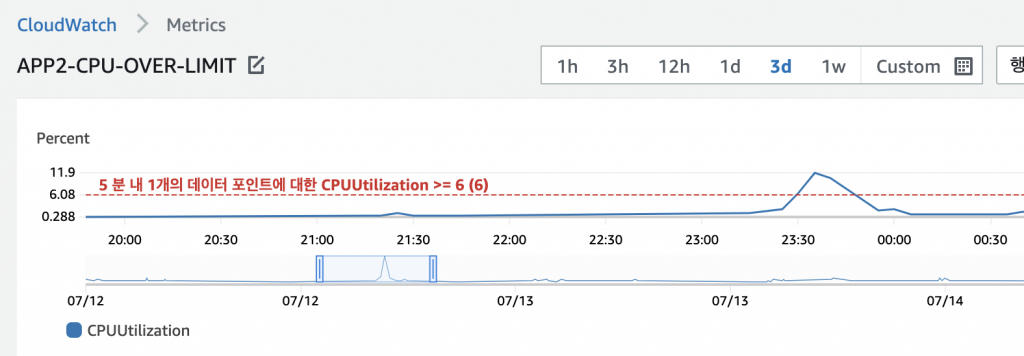
< 저는 서버들의 CPU Utilization 의 5 Minute Average 가 6이 넘는경우, 서버를 자동 증설합니다 >
Metric 측정 -> Monitoring -> Response, Reaction, Notification 방식으로 처리됩니다.
이 방식의 주요 사용처는 Auto Scaling 입니다.
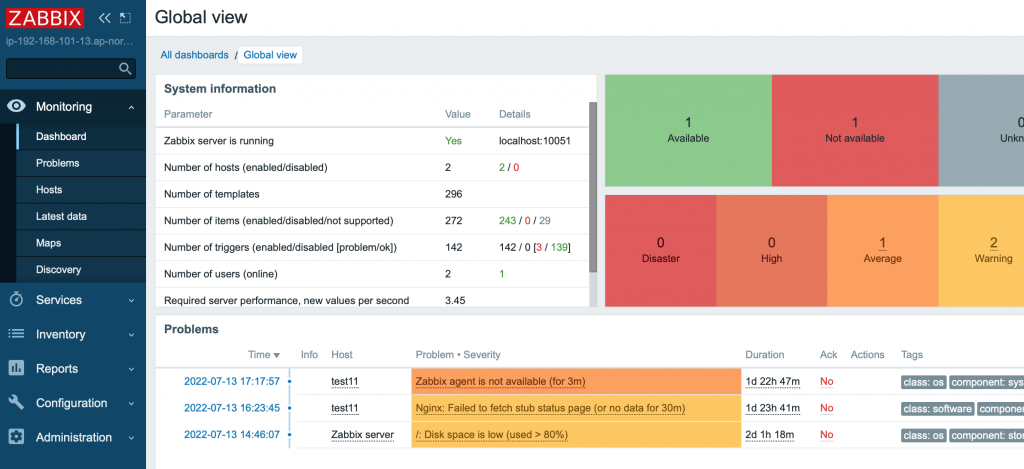
< 모니터링 부분을 깊게 들어가면 생각보다 엄청 어렵습니다 >
Logging, Tracing, Monitoring 의 선택
각 프로세스에는 고유한 목표와 결과가 있으므로 회사에서 하나의 도구만 배포할 필요는 없습니다.
대부분의 경우, Logging 부터 구현합니다.
세 가지 각각이 그 자체로 해결책이 아니라는 점을 기억하는 것이 중요합니다. 시스템이 어떻게 작동하는지 이해하기 위한 도구일 뿐입니다.
요약
Logging 은 Event 에 대한 단순기록. human readable 할 수도 있고, json 형태의 기록일 수도 있음.
Tracing 은 특정 사용자의 하나의 관통화된 이벤트들의 기록.
Monitoring 은 Metric 을 측정하고, 계산식에 따라서 진단 하는것.
이것들 구축 후 알아야 하는 것들은, Notification (Channel 과 Subscribe), Response (함수 서비스, 주로 Lambda).