
대용량 검색 처리를 위한 inverted index (역색인) 설명
#최종 수정 : 2017-03-22 - 내용과 예제를 보강하였습니다.
이 개념은 ElasticSearch 나 Apache Solr 를 다루기 위해 필수적으로 알아야 할 개념입니다.
라엘이의 한마디 : 역방향 인덱스(inverted index)는 원래 대용량 텍스트 검색을 위해서 고안된 방법입니다. 요즘의 SNS에서 주로 사용되는 #태그 검색 기능을 당신의 시스템에 넣고 싶다면 반드시 역방향 인덱스 방법을 사용해야 할 것입니다. (물론 본문을 Full-scan 해서 LIKE 검색을 해도 되지만 매우 비효율적인 방법입니다.)
나름 쉽게 설명한다고 적었는데, 비전공자에게는 어려울 수도 있다.
- 빅데이터
먼저 “빅데이터“란 무엇일까?
http://en.wikipedia.org/wiki/Big_data
위키피디아에서는 “매우 양이 많고 복잡해서 기존에 사용하던 분석방식으로는 처리하기 힘든 데이터들(Data-Set)” 이라고 정의되어 있다.
과거에 비해서 인터넷이 비약적인 성장을 하였고, 언제 어디서나 인터넷에 접속할 수 있는 “유비쿼터스”의 시대 도래로 인해 우리는 항상 인터넷에 연결되어 있다.그러다 보면 많은 종류, 많은 수의 document 를 생성하게 된다.“빅 데이터”(=BIG DATA)(=HIGH VOLUME DATA) 라고 함은 보통 million(백만) document 이상의 data-set을 말하는데 이런 환경에서 사람들은 useful 한 information 을 찾으려고 한다. (중요한 단어는 영어로 쓰겠다.)
따라서 데이터 덩어리(Data-Set)에서 유용한 정보(Useful-Information)을 채굴하는(찾아내는,mining) 것이 중요한 영역이 되었고, 이것에 대해 주로 연구하는 “데이터마이닝(Data Mining)” 분야가 발전하게 되었다.
사용자들은 백만개가 넘게 쌓여진 document 에서 자신에게 필요한 document를 찾고자 한다.
예를들어 100만개의 글(documents)이 있는 게시판에서 User가 “Buying a Home” 이라고 검색을 한다고 가정해보자.
기존의 전통적인(Traditional) 검색방식은 아래와 같다.
1) WHERE = 검색방식
SELECT * FROM `M_DOCUMENT` WHERE `bookname` = 'Buying a Home'
이 경우 검색어와 정확히 일치하는 문서만 선택이 된다.
즉, 문서 결과를 거의 얻지 못한다.
2) WHERE LIKE 검색방식
SELECT * FROM `M_DOCUMENT` WHERE `bookname` LIKE '%Buying a Home%'
이 경우 검색어가 문서내용(bookname 필드)에 포함되어 있는 경우 선택이 된다.
1번 방식보다 진화한 방식이지만 여전히 해당 문장이 정확히 일치하는 경우가 적기 때문에 결과를 거의 얻지 못한다.
3) Whitespace tokenizer AND 검색방식
사용자의 쿼리를 Whitespace 로 쪼개서 AND 검색을 실시한다.
SELECT * FROM `M_DOCUMENT` WHERE `bookname` LIKE '%Buying%' AND `bookname` LIKE '%a%' AND `bookname` LIKE '%Home%'
문서내용(bookname 필드)에 사용자 검색어의 모든 단어가 포함된 경우를 찾는다.
이전 방식과 비교해서 상당히 많이 향상된 결과를 보여주지만 해당단어가 모두 포함된 문서가 아니면 결과에 포함되지 않는다.
4) Whitespace tokenizer OR 검색방식
사용자의 쿼리를 Whitespace 로 쪼개서 OR 검색을 실시한다.
SELECT * FROM `M_DOCUMENT` WHERE `bookname` LIKE '%Buying%' OR `bookname` LIKE '%a%' OR `bookname` LIKE '%Home%'
문서내용(bookname 필드)에 사용자 검색어 중 하나라도 포함되는 경우를 찾는다.
사용자가 원하는 문서를 찾아준다는 점에서 매우 우수한 검색방식이다. 하지만 어느하나의 단어만 포함되도 되기에 전혀 관계가 없는 문서도 결과물(result-set)로 추출된다.
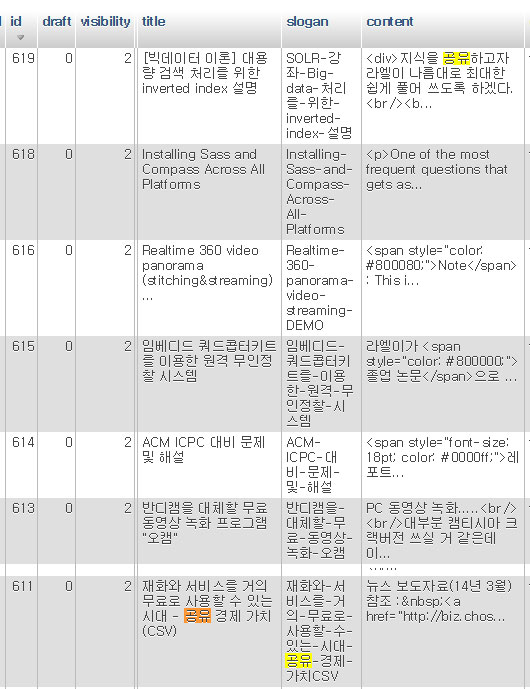
<그림 : 현재 블로그의 DB 내용 중 일부>
예를 들어 ‘공유‘ 라는 단어를 검색하면 이 블로그의 전체 글의 `content` 필드를 모두 읽어들여서 ‘공유’ 라는 단어의 포함여부를 확인한다.
WHERE `content` LIKE ‘%공유%’ 의 구문이 동작하는데 데이터를 모두 읽어서 처리하기 때문에 결과를 얻기까지 많은 노력과 시간이 필요하다.
인덱싱이 되지 않는다고 표현하는데 쉽게 풀이하자면 위의 DB 쿼리 구문은 모든 글에 대해서 `content` 항목값을 읽은 후에 찾아야하고 이보다 더 나은 방법이 존재하지 않는다는 뜻이다.
만약 지금 보고 있는 라엘이의 블로그에 적용된 방식처럼 `title` 및 `slogan` 필드 값에서도 ‘공유’라는 단어를 찾고 싶다면 검색에 들어가는 노력은 3배가 될 것이다.
(더 나은 방식을 적용할 수가 없다!)
이것은 매우 비 효율적인 방식이다. 생각을 해 보아라. 검색할 때마다 million documents 의 `body` 필드를 읽어들여서 찾아낸다는 것은 말도 안되는 것이다.
*4번의 방식은 현재 한국 내 커뮤니티에서 가장 많이 사용하고 있는 검색방식이다.
따라서 국내 커뮤니티 검색엔진에서 좋은 결과를 얻고자 한다면 키워드 입력방식을 사용해야 한다.
예를들어 “집을 살때 필요한 서류” 를 검색하고 싶으면 “집 서류” 라고 검색해야 가장 훌륭한 결과물을 얻어낼 수 있다.
쿼리 : SELECT * FROM `M_DOCUMENT` WHERE `bookname` LIKE ‘%집%’ OR `bookname` LIKE ‘%서류%’
4번이 정말 좋은 방식이긴한데 몇가지 단점이 있다.(여러분이 별 생각없이 검색기능을 구현하려면 4번 처럼 하세요. 게시글 2만개 까지는 위의 검색방식이 아주 효과적임)
- 의미없는 결과값도 나옴.
- 검색 대상이 누적되면서 (100만개 정도의 big data가 되면서) 검색부하가 엄청 오래 걸림.
예를 들어 4번과 같은 쿼리를 100만개 data-set 에 질의(query) 하면 1시간 넘게 걸린다.
(각 문서는 1000자 정도의 내용을 담고 있다고 가정)
2016년 1월 현재 4번과 같은 검색이 가장 효율적으로 평가되고 있는 상태이고, 여러 대형 커뮤니티들은 나름의 해결법을 찾아 운영하고 있다.
1) 검색 대상 문서의 범위 제한을 걸었음. (일정 갯수단위로 구간을 나눔)
2) 의미없는 결과가 나오기도 하나(검색어의 단어 중 일부가 포함되어 결과에 추출된 것) 검색결과는 사용자가 판단하도록 함.
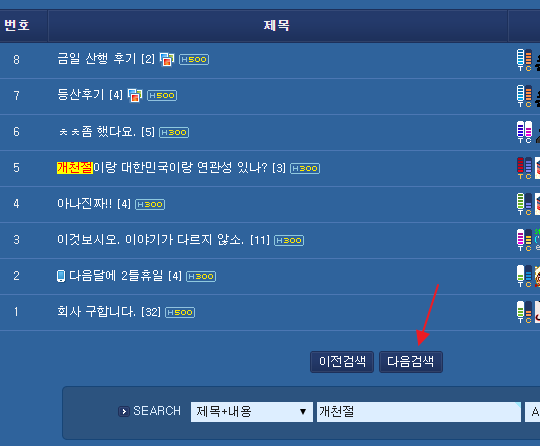
<사진 : PHPSCHOOL 의 경우 20000개 문서 단위로 검색을 하고 있다>
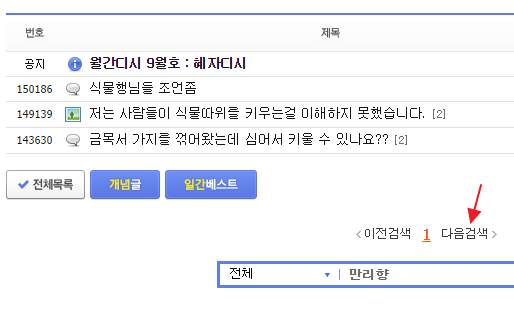
<사진 : DC 인사이드의 경우 10000개 문서 단위로 검색을 하고 있다>
글번호 (document id)는 index가 되기 때문에 document id 로 구간을 나누어서 검색하게 하면
데이터 셋이 작아지게 되고 기존의 4번의 방법을 사용해도 빠른 속도로 결과 출력이 가능하다.
여러분의 소프트웨어에서 검색엔진을 만든다면 4번의 방법을 사용하세요!
데이터가 5만개가 넘지 않는다면 매우 훌륭한 결과물과 매우 훌륭한 속도의 검색을 만들 수 있습니다.
이것보다 더 나아가서 검색이 조금 더 인간의 사고 과정과(생각하는 단계) 유사하게 만들고자 하는 시도가 있었고 이러한 시도를 의미있는 검색 (Semantic Search)이라고 부르게 되었다.
먼저 검색의 속도를 향상시키려고 했다.
1. Inverted index
Traditional SQL 에서는 LIKE 검색이 INDEX 기능을 이용할 수 없다는 단점이 있어서, 그 문제를 극복하기 위해서 단어(Term)로 인덱싱을 하는 Inverted Index 방식이 고안되었다.
기존의 데이터베이스가 하나의 구분자(Primary Key)가 여러 필드를 지정하고 있었다면
Inverted Index에서는 하나의 값(Term)이 해당 Term이 들어간 document id 를 지정하고 있다.
아래 그림을 보자.
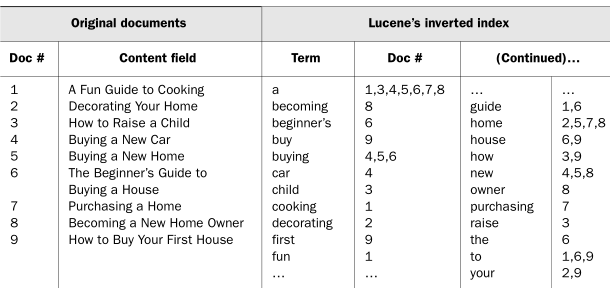
<사진 : Inverted Index 예시>
1~9 document 데이터를 분석해서 테이블을 구성한다.
오른쪽 inverted index table을 보자.
becoming home 이라고 검색하면 becoming 과 home 으로 나눈 후에 빠르게 (8), (2,5,7,8) 이라는 결과가 반환이 되고
8이 가장 유사한 결과물이라고 알게 된다.
인덱싱(Indexing;미리 순서대로 정렬해서 저장해두는 방식)을 하기 때문에 탐색 속도가 매우 빠르다.
2. Inverted index with Term position
단어 값(Term)이 추가 정보를 지정할 수 있게 된다.
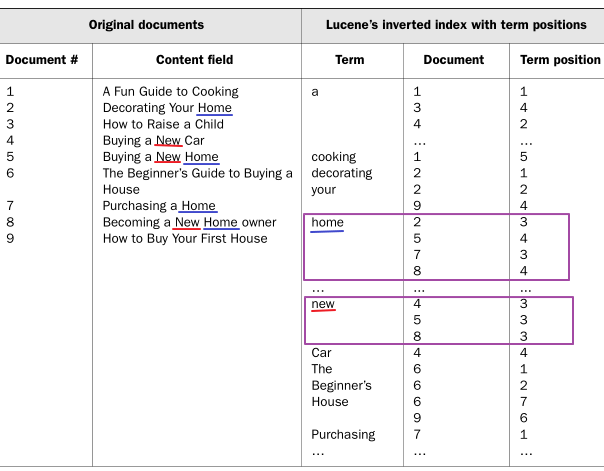
이 기능은 검색결과를 향상 시키기 위해서 사용된다.
단어 값(Term)이 발견된 위치도 저장한다.
예시로 사용자가 new home 을 검색했다고 가정하면, 위의 그림에 따라 5번과 8번 document 를 반환하게 된다.
5번과 8번이 두 단어를 모두 포함하는 document 일뿐 아니라, new 다음에 home 이 나타나는 문서임을 알 수 있다. (Term position 순서비교)
단어가 연속되는지 (new home) 여부를 빠르게 파악이 가능하고 단어(Term) 사이의 값을 찾을 수도 있다.
이것을 활용해 new home, new brand home , new super cheap home 등이 결과에 나올 수 있게 된다.(Proximity Search)
- 위의 inverted index 까지 쓴 것이 (도입 유래와 동작원리) 이 글의 목표지만, 글 흐름상 하나 더 다뤄도 될 것 같아서 계속 작성한다.
이제 검색의 품질을 향상시키려고 했다.
검색의 품질은 “검색되야 하는 것이 나오는지?“, “검색 안되어야 하는게 안나오는지?“, “제한시간 안에 결과가 나오는지” 등 다양한 기준으로 평가가 가능하다.
이중에 “검색 되어야 하는 것이 나오는지?” 에 대해서 살펴보자.
일반적인 경험에 따르면 10% 의 사용자가 2페이지를 살펴본다.
그리고 1%의 사람이 3페이지 이상을 살펴본다.
검색 결과의 순위가 중요하다는 것이다.
검색 엔진이라 함은 국내의 N모 회사처럼 자사의 블로그, 카페, 유료 광고 검색 결과 후에 결과를 출력하면 안되고(장기적으로 보면 제살 파먹기이다)
사용자가 원하는 document를 더 상단으로 표시해 주어야 한다. (검색을 하는데 필요없는 정보만 잔뜩 나오면 사용자는 짜증날 것이다)
- Relevancy (유사도)
검색엔진은 사용자가 검색한 단어를 기반으로 유사한 문서를 먼저 출력해 주어야 한다.
사용자의 검색어와 document 의 Relevancy를 평가한다. (Scoring)
유사도는 Term vector의 cosine similarity 로 구한다.
아래 그림처럼 쿼리 q 에 대해서 문서 d1 이 문서 d2 보다 angle이 작기 때문에 cosine 값이 커지게 되고 더 유사한 것으로 판단된다.
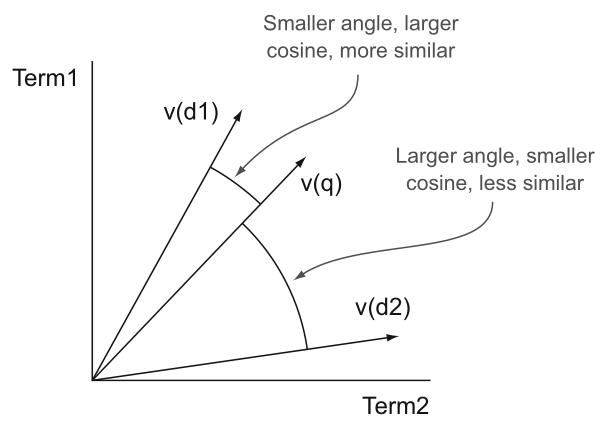
유사도 계산(Relevancy calculation)은 검색엔진마다 다양한 방식으로 평가되나 일반적으로 널리 쓰이는 방식을 살펴 보도록 하겠다.
아래는 Apache Lucene의 DefaultSimilarity class 에서 사용하는 scoring 방식이다.

고려하는 항목 설명
- Term frequency (tf)
문서에 단어의 빈도가 많으면 score가 올라간다.
- Inverse document frequency (idf)
흔하지 않은 단어가 사용되면 score가 올라간다.
- Boosting
특정단어에 임의로 가중치를 주어서 해당 단어가 사용되면 score가 더 높게 올라간다.
--
끝.
지식을 배우는 것과, 바로 앞에 사람을 두고 이해도를 보며 과외하는건 쉽지만,
역시나 어려운 내용을 쉽게 글로 풀어쓴다는건 힘든 작업인 것 같다.
위 내용과 관련한 다음강좌를 쓸 수 있을지는 모르겠다.
좋은 글 감사합니다~ 공부 자료 정리 중에 도움 받았습니다
안녕하세요! 역색인에 찾고있었는데 글 너무 잘 읽었습니다.
혹시 괜찮으시다면 개인 블로그에 퍼가도 될까요?!
네. 가능합니다. 감사합니다.
Nice Article!
정말 감사합니다! 입문자인데 쉽게 이해됐어요
화이팅입니다!
유익한 글 감사합니다! 파일 브라우저를 만드려고 하는데 ‘2. Inverted index with Term position’ 은 간단한 형태로 구현하고 싶어요. 손으로 구현하는게 좋을까요? 아니면 간단한 형태라도 상용 라이브러리를 쓰는게 좋을까요?
파일 검색을 넣으시려는 거군요.
언제나 직접 구현하는게 가장 좋습니다.
다만, 복잡해서 그런지 몰라도, 파일브라우저의 검색은 보통 현재 위치 파일목록에 대한 검색만 하더라구요.
아하 만들어 봐야겠네요, 고맙습니다!
글이 정말 유익했습니다. 쉽게 이해가 되네요!
감사합니다!
잘읽었습니다. 감사합니다.
질문이 있다면, 기존에 테이블에 건수가 몇천만건 있는데 이걸 인덱싱 걸려면 기존 쿼리를 Solr에 맞게
수정해서 등록해야 하나요?
아니면 테이블 전체를 Full로 인덱싱 해야 되나요?
기존쿼리를 변환하는건 저주에 가깝더라구요. 되지도 않고……
조언 부탁드립니다.
정렬/검색 기준이 텍스트 데이터가 아니라면 기존의 rdbms로도 충분히 사용할 수 있습니다. (3000만건 데이터로 테스트 했음.)
텍스트 데이터 또는 텍스트데이터를 포함해서 정렬/검색 한다면 이러한 대용량 처리를 구축하셔야 합니다.
먼저, 기존의 모든 데이터를 select 해서 solr에 insert 하면 자동으로 인덱싱 처리됩니다. 필요한 페이지에서 기존의 rdbms 쪽으로 쿼리하지 않고 solr 로 쿼리하면 됩니다.
예를 들자면 https://cohabe.com/ 사이트는 현재 150만건의 텍스트 데이터가 있고 검색페이지에서만 대용량 검색을, 그외의 페이지는 mysql을 사용합니다.
요약하자면
1. 데이터를 모두 select 해서 빅데이터 쪽으로 밀어넣어야 쿼리를 날릴 수 있음. (대부분 필드타입 자동감지 및 자동으로 인덱싱이 됨)
2. 완전이 대체하는 것이 아니라, 필요한 부분에서만 사용할 것.
3. 빅데이터 처리는 만능이 아님. 제약조건이 많다. (다중 where, order by, group by, having등)
좋은 글 감사합니다.
좋은글 잘 보았습니다. 글을 작성하기 위해 글쓴이님의 노력이 느껴집니다!
감사합니다.
조만간 elastic search 를 활용해서 직접 사용하는 예제 글을 적어봐야겠어요.
글 잘읽었습니다.
감사합니다!
덕분에 inverted index에 대해 쉽게 이해했습니다.
이해하기 쉽게 좋은 글 적어주셔서 많이 배우고 갑니다.
감사합니다! 요즘 이 글의 조회수가 올라가네요. 대용량 처리에 대해서 글 더 써볼까 고민하고 있습니다.
와! 정말 좋은 글 감사합니다.^^
튜토리얼 성격의 글입니다.
이 주제의 글 수요자가 별로 없을 것 같아서 추가 글이 없습니다.
좀 더 자세히 배우시려면 관련 서적 구매를 고려해보세요.
좋은 글 감사합니다.