
빅데이터 처리 후기 (검색엔진 처리)
빅데이터 처리 후기를 써본다.
진행 중인 사항이기 때문에 후기보다는 경과보고가 맞는것 같다.
이 글은 검색엔진 최적화(SEO)와 관계가 없다.
1. DB 설계를 최적화 해야할 것 (쿼리의 최적화)
이게 무슨 뜻이냐면, 쿼리를 아주 단순하게 날릴 수 있어야 한다는 것이다.
SELECT, FROM, JOIN ON 막 이렇게 복잡하게 날리면 복잡도가 늘어난다.
DB를 처음배울때 중복을 제거하는 정규화라는 것을 배우는데, 이 정규화를 깨버리면 성능이 올라간다.
물론 중첩에 대해서는 관리를 잘 해주어야한다.
쿼리는 되도록 PK 가 포함되도록 요청하는게 좋고, 조금만 복잡해 질것 같으면 SQL 에서 조건 제외하고, 실행 결과를 받아서 프로그램단에서 처리해야 한다.
2. 페이징 최적화를 해야할 것
전체 document 의 개수가 10만건이 넘었을 때, 2만 이상의 index 를 실행하면 응답이 매우 느린 것을 알 수 있다.
즉 페이지당 글이 15개이고, 1001 페이지를 불러올 경우 SQL 에 LIMIT 15000, 15 라고 쓰는데, 이게 실행이 잘 안된다.
자세한 사항은 여기에 적기 부적절하고, 아무튼 페이징 최적화가 필요하다. (저렇게 쿼리를 날리면 안됨)
3. 검색엔진을 도입 할 것
이것은 내가 예전에 쓴 글을 참고해보면 된다. (대용량 검색 처리를 위한 inverted index (역색인) 설명 : https://blog.lael.be/post/3056)
일반적은 SQL 검색은 2만 document 가 넘어가면 잘 안돌아간다. (결과 출력까지 엄청 오래걸림)
근데 검색엔진은 SQL 과 분야가 달라서, 배워야 할게 좀 있다.
나의 시행착오(trial and error) 몇가지
나는 현재 검색 데이터로 10GB, 200만 document 를 가지고 있다.
1) SQL Fulltext Search
MySQL 5.7 에 추가된 기능이다. fulltext 와 ngram 옵션을 통해 기존의 LIKE 검색의 문제를 극복할 수 있다.
쿼리의 결과물도 훌륭하다.
다만 쿼리를 잘못날리면 서버가 crash 나더라. (mysql 프로세스가 갑자기 종료되고 다시 켜짐)
앞으로 최소 2년간은 사용하면 안된다고 생각한다.
2) Opensolr 호스팅
https://opensolr.com/pricing

10GB 를 사용하려면 Enterprise 가 되어야한다.
3) searchify
http://www.searchify.com/plans/
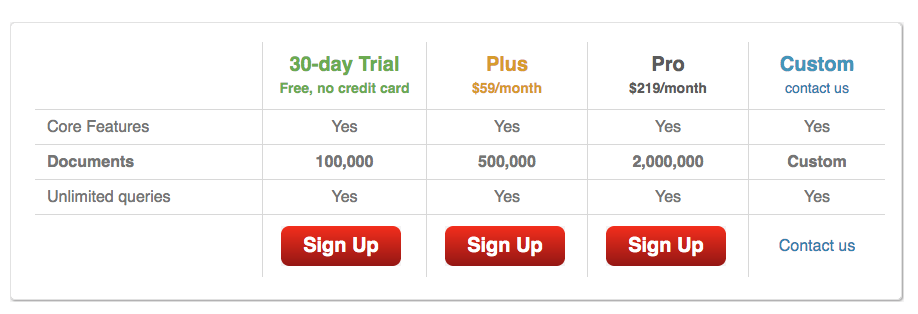
어느 다른 옵션보다 저렴하다. 나의 경우 Pro를 써야할듯하다. 테스트는 못해봄.
4) Algolia
사용법이 쉽다. 관리자 콘솔이 잘 만들어져있다.
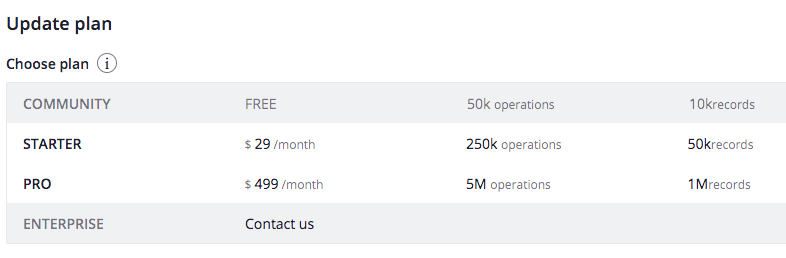
나의 경우 Pro 이상을 써야하고, 월 60만원은 지불할 수 없다. (수익이 그정도 나오지 않음)
5) Amazon Cloud Search
https://aws.amazon.com/ko/cloudsearch/pricing/
AWS는 비용 계산이 복잡해서 따로 적지는 않는다. 제일싸게 처리해도 약 60만원정도 나올 것으로 예상됨.
6) NCloud Search
https://www.ncloud.com/product/analytics/cloudSearch
비용은 따로 적지 않는다.
7) Elastic Search 직접 구축 운영
이것저건 번거로우면 직접 운영하면 된다. 라엘이의 경우 이렇게 하고 있다.
좋은 퀄리티와 빠른 반응속도, 용량내 무제한 문서 처리. 월 운영비용 2만원.
단점은, 검색 퀄리티를 높이고 싶은데 생각만큼 잘 개선되지 않는다.
원하는 문서가 나와야하고, 원하지 않는 문서는 나오지 않으면 된다. 이게 정말 말은 쉬운데, 구현하기 매우 어렵다.
4. ALTER TABLE 은 콘솔에서 작업할 것
document 가 많아지면 테이블 변경작업에(varchar(100)을 varchar(200) 으로하거나, 새 필드를 추가하거나) 시간이 매우 많이 걸린다.
리눅스 screen 과 콘솔 접속을 통해서 실행해야한다.
결론 :
내가 다룬 것중 가장 큰 volume 은 테이블에 3000만개 데이터가 있던 것이고, 0.001 초 이내에 쿼리 결과가 나왔었다.
(StarLog.GG 개발기 : https://blog.lael.be/post/8476 )
물론 이 검색은 text-centric 한 검색은 아니었다. (Korea 서버의 Lael 계정이 Hunter 맵에서 나는 Protoss, 상대는 Zerg 일때 - 승률 구하기)
텍스트 검색(text-centric)은 다루기 어렵다. 어느 정도 까지는 하겠는데 그 한계를 극복하기가 어려운것 같다. (검색엔진 스터디 같은게 있으려나..)